
Análise por aprendizado de máquina sugere que associação de mulheres à família e de homens à carreira pode ser reflexo da estrutura de mais de 25 idiomas.
A forma como as palavras são utilizadas tem papel importante na construção de representações sociais. Palavras que representam um mesmo conjunto de ideias geralmente aparecem próximas com mais frequência do que esperado pelo acaso, o que faz com que os termos “gato” e “cachorro’, por exemplo, apareçam juntos mais vezes do que “gato” e “banana”. De forma sutil, a associação entre palavras pode gerar estereótipos e perpetuar preconceitos. Esse parecer ser o caso dos estereótipos de gênero.
Uma dupla de pesquisadores estadunidenses utilizou técnicas de aprendizado de máquina para analisar textos em 25 idiomas. Na pesquisa, modelos computacionais foram treinados para prever a ocorrência de palavras a partir de outros termos que apareciam em seu entorno. O treinamento se baseou em textos da Wikipedia e em legendas de filmes e programas de televisão. Os resultados foram publicados esta semana na revista científica Nature Human Behaviour e mostram que a palavra “mulher”, em comparação à palavra “homem”, geralmente aparece mais associada a termos como “família” e “casa” e menos ligada a termos como “carreira” e “profissão”.

Mas o interesse dos responsáveis pela pesquisa foi além dos textos. Molly Lewis, que investiga cognição na Universidade Carnegie Mellon, e seu colega Gary Lupyan, da Universidade de Wisconsin, queriam saber se os falantes de cada língua compartilhavam os estereótipos sugeridos pela análise textual. Para isso, utilizaram dados do Projeto Implícito, um estudo de amplo alcance com resultados de mais de 600 mil pessoas em 39 países.
Os dados de interesse para Molly e Gary eram testes de associação implícita (TAI), nos quais os participantes eram apresentados a palavras que deveriam ser classificadas em categorias ligadas a “homem” e “carreira” ou a “mulher” e “carreira”. Em uma fase do teste, as categorias são combinadas de forma convergente com estereótipos de gênero e, na outra fase, de forma divergente. A classificação deve ser feita no menor tempo possível para captar associações que não passam por um processo longo de reflexão e diferenças no tempo de associação das palavras aos pares convergentes e divergentes indicam o quanto os estereótipos estão arraigados. Os resultados do TAI mostram forte relação com aqueles do aprendizado de máquina: pessoas de países cujo idioma principal tem estereótipos fortes também apresentam maior força em seus estereótipos implícitos de gênero.
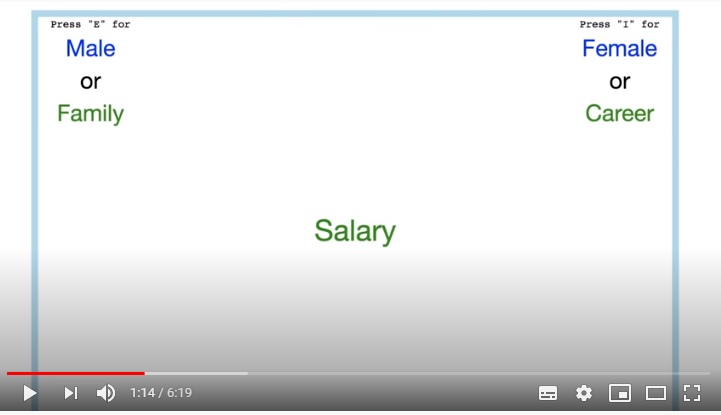
Apesar da evidente relação, a dupla de pesquisadores destaca que não é possível estabelecer uma relação direta de causa e efeito. Ou seja, a língua falada pode moldar a representação psicológica sobre mulheres e homens, mas talvez ela seja apenas um reflexo de estereótipos construídos a partir de outros fatores sociais. É preciso investigar o quanto padrões no idioma são suficientes para produzir crenças e o quanto essas associações são resistentes a outras fontes de representação de gênero.
De qualquer maneira, estereótipos em relação a carreiras têm consequências no mundo real e o estudo aponta que, nos países em que a língua dominante apresenta estereótipos fortes, a participação de mulheres em áreas de ciência e tecnologia é mais baixa. Para Molly Lewis, entender as relações entre idioma e estereótipos permite intervir sobre como a sociedade expressa suas ideias e minimizar eventuais danos causados pela estrutura linguística.
News: Luanne Caires
Fontes:
Artigo científico intitulado “Gender stereotypes are reflected in the distributional structure of 25 languages”, publicado na revista Nature Human Behaviour em 2020, de autoria de LEWIS Molly e LUPYAN Gary.
https://www.nature.com/articles/s41562-020-0918-6
Matéria no site Scientific American intitulada “How dozens of languages help build gender stereotypes”, publicada em 03/08/2020.
https://www.scientificamerican.com/article/how-dozens-of-languages-help-build-gender-stereotypes/
(Editoração: André Pessoni)